"You are not a parrot. And a chatbot is not a human."
How should we interpret the natural-sounding (i.e., humanlike) words that come out of LLMs? The models are built on statistics. They work by looking for patterns in huge troves of text and then using those patterns to guess what the next word in a string of words should be. They’re great at mimicry and bad at facts.
https://nymag.com/intelligencer/article/ai-artificial-intelligence-chatbots-emily-m-bender.html

selection from "Once More—A Computer Revolution", by Joseph Weizenbaum. (The Bulletin
of the Atomic Scientists 34:14, Sept. 1978) h/t Paige Bailey @dynamicwebpaige
"ChatGPT is a Blurry JPG of the Web"
-- https://www.newyorker.com/tech/annals-of-technology/chatgpt-is-a-blurry-jpeg-of-the-web
"We come to bury ChatGPT, not to praise it"
the problem is, trusting any form of machine learning is what leads to a single mother having their front door kicked open by social security officials because a predictive algorithm has fingered them as a probable fraudster, alongside many other instances of algorithmic violence.
-- Dan McQuillan, https://www.danmcquillan.org/chatgpt.html
"School librarians should approach ChatGPT with caution"
When I asked it to compile a list of graphic novels for middle schoolers, I got the same few popular titles, despite rephrasing the prompts. The same few titles were regurgitated back to me, and some of the reasoning for why a title was selected was misleading. Our current databases, even Goodreads and Amazon, are doing better at recommending titles. Each month, more diverse titles are being published than even three years ago. By design, these critically important books will be omitted from recommendations until the software is updated.
AI will (most likely) not gain sentience in our lifetime. But what it is doing right now is replacing human labor with bad facsimiles, making public communication worse, automating prejudices, strengthening monopolies, and creating new ways to terrorize each other.
— Ryan Broderick (@broderick) February 16, 2023
"Are librarians the next prompt engineers?" - Laura Solomon
This quote really got me thinking: “There are prompts that promise to generate new sports-team logos, and text hacks with names like Sentence Expander. For $3.99, Book Summarizer promises a prompt that will help “extract the essential information and takeaways from a book.”” Not the “it can summarize a book part.” The part that says “For $3.99.” This cottage industry, although a side hustle for many, is essentially monetizing the search for information.
-- From Laura Solomon's blog: https://meanlaura.com/are-librarians-the-next-prompt-engineers/
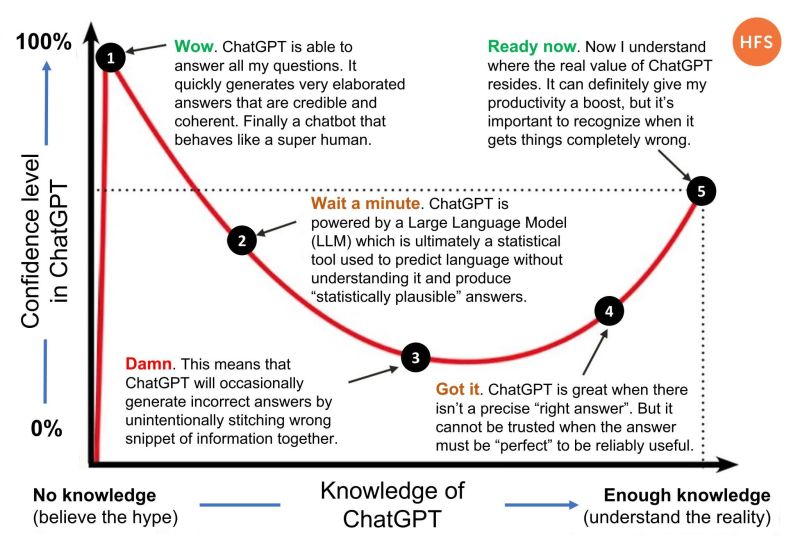
ChatGPT vs Dunning-Kruger. Searched for source but only found retweets, Reddit threads, Kaggle posts, etc. If you are able to find the author, please contact us so we can update this reference!
23 Resources to Get Up to Speed on AI in 2023 - IFLA
https://www.ifla.org/g/ai/23-resources-to-get-up-to-speed-on-ai-in-2023/
From the International Federation of Library Associations and Institutions
Booked for Brilliance: Sweden’s National Library Turns Page to AI to Parse Centuries of Data
The library is training state-of-the-art AI models on a half-millennium of Swedish text to support humanities research in history, linguistics, media studies and more.
Twenty-six petabytes, adding 50 terabytes a month!!
https://blogs.nvidia.com/blog/2023/01/23/sweden-library-ai-open-source/
"The Efficacy of ChatGPT - Is it Time for the Librarians to Go Home?"
The main problem found with ChatGPT is that the citations refer to articles that don’t exist (see Appendix II: Citations). They are phantom citations leading nowhere. Each citation was searched on Proquest’s Library and Information Science Collection, and the most common response was: “Your search for “article title” found 0 results.” Of the 29 citations checked, only one was accurate, one was correct but had the title transposed, and one was to a real article, but the source journal provided by ChatGPT was incorrect.
Guess the librarians better not go home :-)